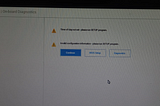
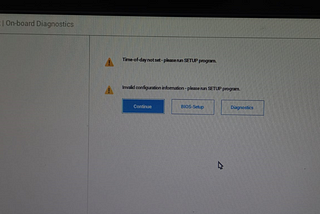
Shubhasmita Roy“Time of Day not set” error on Dell PCIf you see the following show up when you switch on your PC then this article is going to of help to you 🙂.4 min read·Aug 20, 2023----
Shubhasmita RoyPreparing for GCP Associate Cloud Engineer (ACE) CertificationDear readers, keep calm and let’s prepare for the exam!8 min read·Aug 12, 2023--1--1
Shubhasmita RoyProgress: 6 month self development journeyI want to keep this blog as an open journal that I update on a regular basis, so that it acts as my motivation — a reward system of sorts.5 min read·Dec 11, 2021----
Shubhasmita RoyFor those who get an error on importing vggface related packages:1. install this for keras_application error1 min read·Sep 4, 2021----
Shubhasmita RoyinGeek CultureAgglomerative Hierarchical Clustering — a gentle intro with an example programWe are venturing into the uncharted territory of Unsupervised Learning here…7 min read·Jun 23, 2021----
Shubhasmita RoyinAnalytics VidhyaReconstructing a li’l girl’s portrait using Principal Component AnalysisPCA, Principal Component Analysis, is one of the basic techniques for reducing data with large dimensions to a much smaller set. The idea…3 min read·May 13, 2021----
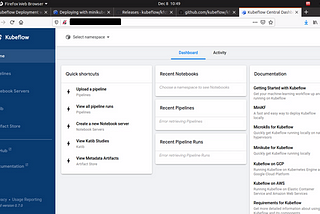
Shubhasmita RoyinLevel Up CodingDeploying Kubeflow on a local Kubernetes cluster (minikube)This is a tutorial on deploying Kubeflow on a local Kubernetes cluster from scratch. While trying to deploy it myself using the…7 min read·Dec 19, 2020--1--1